Các mô hình ngôn ngữ lớn (LLM) hiện đang là trung tâm của thế giới AI. Tại sao cơ sở dữ liệu vector lại quan trọng đối với LLM?
Khi bạn đang lướt qua dòng thời gian của mình trên Twitter, LinkedIn hoặc nguồn cấp tin tức – bạn có thể thấy điều gì đó về chatbot, LLM và GPT. Rất nhiều người đang nói về LLM vì những cái mới được phát hành hàng tuần.
Vì chúng ta hiện đang sống trong cuộc cách mạng AI, điều quan trọng là phải hiểu rằng rất nhiều ứng dụng mới này dựa vào việc nhúng vectơ. Vì vậy, hãy tìm hiểu thêm về cơ sở dữ liệu vectơ và tại sao chúng quan trọng đối với LLM.
Cơ sở dữ liệu Vector là gì?
Đầu tiên chúng ta hãy xác định việc nhúng vector. Nhúng vectơ là một kiểu biểu diễn dữ liệu mang thông tin ngữ nghĩa giúp hệ thống AI hiểu rõ hơn về dữ liệu cũng như có thể duy trì trí nhớ dài hạn. Với bất kỳ điều gì mới mà bạn đang cố gắng học, yếu tố quan trọng là hiểu chủ đề và ghi nhớ nó.
Các phần nhúng được tạo bởi các mô hình AI, chẳng hạn như LLM có chứa một số lượng lớn các tính năng khiến việc quản lý việc trình bày của chúng trở nên khó khăn. Việc nhúng thể hiện các kích thước khác nhau của dữ liệu, giúp các mô hình AI hiểu được các mối quan hệ, mẫu và cấu trúc ẩn khác nhau.
Việc nhúng vectơ bằng cách sử dụng cơ sở dữ liệu dựa trên vô hướng truyền thống là một thách thức vì nó không thể xử lý hoặc theo kịp quy mô và độ phức tạp của dữ liệu. Với tất cả sự phức tạp đi kèm với việc nhúng vectơ, bạn có thể hình dung ra cơ sở dữ liệu chuyên biệt mà nó yêu cầu. Đây là nơi cơ sở dữ liệu vector phát huy tác dụng.
Cơ sở dữ liệu vector cung cấp khả năng lưu trữ và truy vấn được tối ưu hóa cho cấu trúc nhúng vectơ độc đáo. Chúng cung cấp khả năng tìm kiếm dễ dàng, hiệu suất cao, khả năng mở rộng và truy xuất dữ liệu bằng cách so sánh các giá trị và tìm ra điểm tương đồng giữa nhau.
Nghe có vẻ tuyệt vời phải không? Có một giải pháp để xử lý cấu trúc phức tạp của việc nhúng vectơ. Đúng nhưng không phải thế. Cơ sở dữ liệu vector rất khó thực hiện.
Cho đến nay, cơ sở dữ liệu vectơ chỉ được sử dụng bởi những gã khổng lồ công nghệ có khả năng không chỉ phát triển mà còn có thể quản lý chúng. Cơ sở dữ liệu vectơ đắt tiền, do đó việc đảm bảo rằng chúng được hiệu chỉnh đúng cách là điều quan trọng để mang lại hiệu suất cao.
Cơ sở dữ liệu Vector hoạt động như thế nào?
Vì vậy, bây giờ chúng ta đã biết một chút về cơ sở dữ liệu và nhúng vectơ, hãy đi sâu vào cách hoạt động của nó. 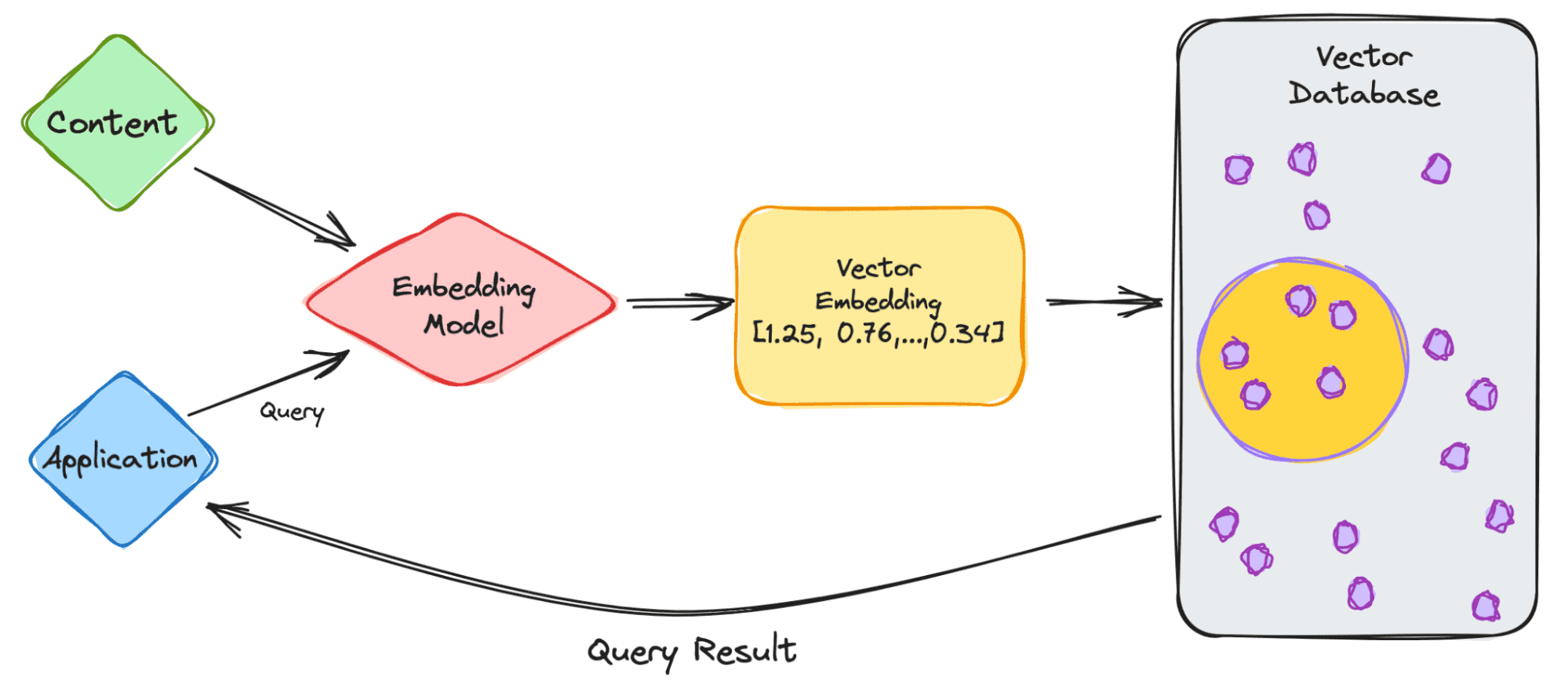
Hãy bắt đầu với một ví dụ đơn giản về xử lý LLM như ChatGPT. Mô hình có khối lượng dữ liệu lớn với nhiều nội dung và họ cung cấp cho chúng tôi ứng dụng ChatGPT.
Vì vậy, chúng ta hãy đi qua các bước.
- Với tư cách là người dùng, bạn sẽ nhập truy vấn của mình vào ứng dụng.
- Sau đó, truy vấn của bạn được chèn vào mô hình nhúng để tạo các vectơ nhúng dựa trên nội dung mà chúng tôi muốn lập chỉ mục.
- Sau đó, việc nhúng vectơ sẽ di chuyển vào cơ sở dữ liệu vectơ, liên quan đến nội dung mà việc nhúng được tạo ra.
- Cơ sở dữ liệu vectơ tạo ra một đầu ra và gửi lại cho người dùng dưới dạng kết quả truy vấn.
Khi người dùng tiếp tục thực hiện truy vấn, nó sẽ đi qua cùng một mô hình nhúng để tạo các phần nhúng để truy vấn cơ sở dữ liệu đó để tìm các phần nhúng vectơ tương tự. Điểm tương đồng giữa các phần nhúng vectơ dựa trên nội dung gốc mà phần nhúng được tạo trong đó.
Bạn muốn biết thêm về cách hoạt động của nó trong cơ sở dữ liệu vector? Hãy tìm hiểu thêm.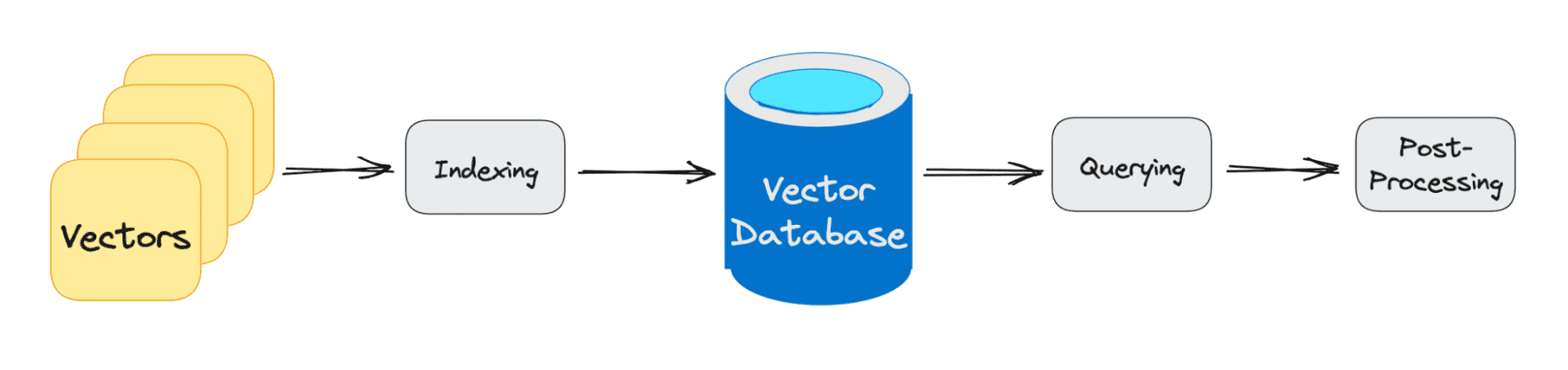
Hình ảnh của tác giả
Cơ sở dữ liệu truyền thống hoạt động với việc lưu trữ chuỗi, số, v.v. theo hàng và cột. Khi truy vấn từ cơ sở dữ liệu truyền thống, chúng tôi đang truy vấn các hàng khớp với truy vấn của mình. Tuy nhiên, cơ sở dữ liệu vectơ hoạt động với vectơ chứ không phải chuỗi, v.v. Cơ sở dữ liệu vectơ cũng áp dụng thước đo độ tương tự được sử dụng để giúp tìm vectơ giống nhất với truy vấn.
Cơ sở dữ liệu vectơ được tạo thành từ các thuật toán khác nhau, tất cả đều hỗ trợ tìm kiếm Hàng xóm gần nhất (ANN). Điều này được thực hiện thông qua băm, tìm kiếm dựa trên biểu đồ hoặc lượng tử hóa được tập hợp thành một đường dẫn để truy xuất các lân cận của vectơ được truy vấn.
Các kết quả dựa trên mức độ gần hoặc gần đúng của truy vấn, do đó các yếu tố chính được xem xét là độ chính xác và tốc độ. Nếu đầu ra truy vấn chậm thì kết quả càng chính xác.
Ba giai đoạn chính mà truy vấn cơ sở dữ liệu vectơ trải qua là:
1. Lập chỉ mục
Như đã giải thích trong ví dụ trên, khi việc nhúng vectơ di chuyển vào cơ sở dữ liệu vectơ, nó sẽ sử dụng nhiều thuật toán khác nhau để ánh xạ việc nhúng vectơ vào cấu trúc dữ liệu để tìm kiếm nhanh hơn.
2. Truy vấn
Sau khi hoàn tất quá trình tìm kiếm, cơ sở dữ liệu vectơ sẽ so sánh vectơ được truy vấn với các vectơ được lập chỉ mục, áp dụng số liệu tương tự để tìm vectơ lân cận gần nhất.
3. Xử lý bài đăng
Tùy thuộc vào cơ sở dữ liệu vector bạn sử dụng, cơ sở dữ liệu vector sẽ xử lý hậu kỳ hàng xóm gần nhất cuối cùng để tạo ra kết quả cuối cùng cho truy vấn. Cũng như có thể sắp xếp lại những người hàng xóm gần nhất để tham khảo trong tương lai.
Kết luận
Khi chúng ta tiếp tục thấy AI phát triển và các hệ thống mới được phát hành hàng tuần, sự phát triển của cơ sở dữ liệu vectơ đang đóng một vai trò lớn. Cơ sở dữ liệu vectơ đã cho phép các công ty tương tác hiệu quả hơn với các tìm kiếm tương tự chính xác, cung cấp kết quả đầu ra tốt hơn và nhanh hơn cho người dùng.
Vì vậy, lần tới khi bạn đặt một truy vấn trong ChatGPT hoặc Google Bard, hãy nghĩ về quá trình nó trải qua để đưa ra kết quả cho truy vấn của bạn.
(dịch từ kdnuggets.com)